Get the code on GitHub
Premise
As of this post, the Consumer Finance Protection Bureau has been active for a little more than 6 years. In that time, they have dealt with over 1 millon complaints regarding financial products.
The complaint process can be summarized as follows:
- Complaints sent to the CFPB are forwarded to the respective companies.
- Company reviews and responds to the complaint.
- Consumer reviews the response, and is given the option to dispute the response with the CFPB.
- Disputed cases might then be flagged by the CFPB for further investigation.
Mission: Build a model to predict whether or not complaints sent to the CFPB will be escalated/disputed.
This model would be especially useful from a customer service standpoint. With this kind of model, customer service departments could prioritize complaints based on relative risk, allowing them to more efficiently deal with large numbers of complaints.
Given the long timeframe associated with the complaint process, this could also be used at the regulatory level to anticipate which complaints will require deeper investigation.
Strategy and Model
Data used for this project comes from the CFPB complaint database and survey of credit card plans. Cleaned data was hosted in a PostgreSQL database in AWS.
Relevant features (including but not limited to):
- product
- issue category
- company response
- complaint submission (web, phone, mail, etc.)
An important note is that because this dataset deals with financial products, it is inherently time-sensitive. As such, train/test splits were done based on moving time windows. Models were trained on a 2-year window, then tested on a 1-week window in the future.
The above pie chart shows the overall dispute rate in the complaint dataset. While 18% positive instances is better than a lot of datasets, it does require some balancing. To address this, I downsampled the negative instances in the training dataset to balance the relative label occurrences.
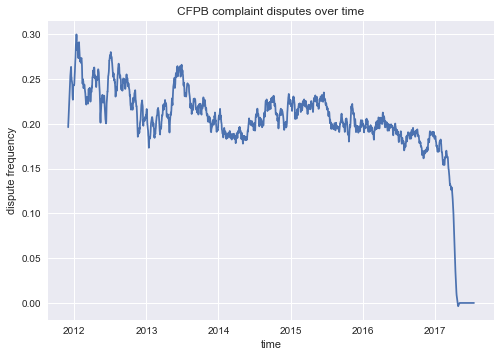
The above plot shows the dispute frequency as it varies over time (smoothed with a Savitzky-Golay filter). The dropoff in 2017 is due to the fact that many of the complaints are still pending. The dispute rate is more erratic from 2012-2014, possibly due to the fact that the CFPB was a new agency at the time, and the complaint process was still in development.
Results
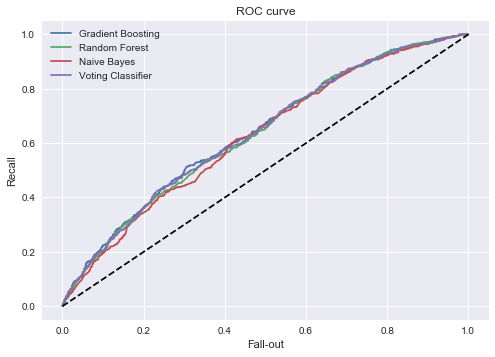
This plot shows the test ROC curve for several models trained on the most recent 2-year window in the dataset. They all have an AUC score in the range of 0.63-0.64. The Voting Classifier returns the mode of the labels predicted by the other three classifiers.
The Gradient Boosting model performs marginally better than the other two base classifiers, and is on par with the Voting Classifier.
It is recommended that the model be retrained weekly, as testing on longer windows causes the AUC to decrease.
Technologies
Python
- scikit-learn
- numpy
- pandas
- matplotlib
- scipy
PostgreSQL
AWS
Closing Thoughts
- “I don’t have to outrun the bear. I just have to outrun you.” - Unknown