Get the code on GitHub
Premise
In the field of online news, there are hundreds of websites reporting on thousands of current events. Limiting our scope to the technical sphere doesn’t improve the numbers significantly. On average, there are 20 articles published per day per website dedicated to technical topics. This presents a challenge in staying informed on specific topics while avoiding the bias of individual websites.
With this in mind, this project focuses on using NLP and unsupervised learning to interpret articles from news websites focusing on technology. This could go a long way towards streamlining our ability to process current events.
For news websites in particular, this has potential applications in selecting articles for headlines, generating daily news categories, and recommending articles to users on similar topics.
Strategy and Model
Thousands of articles were scraped from several technical media websites, such as TechCrunch, ArsTechnica and Engadget. Data was stored in a MongoDB database.
NLP methods were used to preprocess article contents. These methods included the following:
- stopword/punctuation removal
- stemming
- TF-IDF vectorization
- Latent Semantic Analysis
Several unsupervised learning approaches were explored.
- K-means clustering
- Dimensionality reduction and topic modeling via LSA/SVD
- Sentiment Analysis with VADER
Analysis was narrowed to 1-week windows, given the time-sensitive nature of news media.
Results
The corpus was the set of articles published in the most recent week. Individual words were vectorized using TF-IDF scoring. Individual documents/articles were reduced to 400 dimensions using Latent Semantic Analysis (LSA).
Here’s a word cloud showing the words with the highest TF-IDF scores:
(TF-IDF can be thought of as a measure of contextual importance)
K-means clustering (K=20) was then applied on the data.
Cluster descriptions were generated by applying TF-IDF vectorization within clusters, then using the two terms with the highest score as a cluster label. These labels can be used to automatically generate news categories on a daily basis.
t-SNE was used to further reduce the dimensionality. The following shows the clusters plotted in the resulting 2-dimensional space:
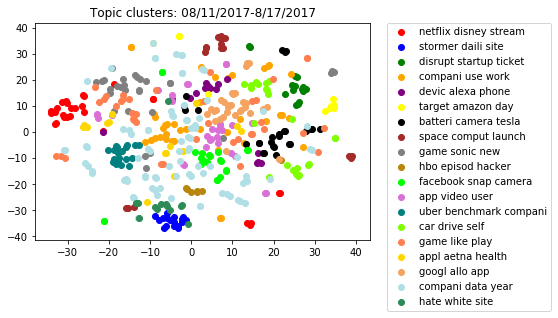
Based on the labels, clusters can be directly mapped to major technology companies (Facebook, Google, Tesla), industries (gaming, consumer electronics), or current events (Charlottesville white supremacy rally, HBO Game of Thrones leaks).
By selecting the most representative article from each cluster (i.e.: closest to each cluster center), we can create a recommendation for headline articles.
Technologies
Python
- beautifulSoup
- scikit-learn
- numpy
- nltk
- pandas
- matplotlib
MongoDB
AWS
Words of Wisdom
- “There is no right answer.” - Most of my teachers