Get the Code!
Premise
12 hours of content are uploaded to SoundCloud every minute. This presents a challenge not in terms of scaling and maintaining an increasing amount of data, but also in terms of processing and recommending new content to users. Unfortunately, the music industry is constantly changing, and artist styles tend to vary over time, so recommendations based on track metadata are not reliable in the long term.
The Music Genome Project is an effort by music analysts to generate an exhaustive list of features to describe music at a fundamental level. This project also forms the backbone of Pandora’s recommendation engine.
With this in mind, the goal of this project is to create a model capable of classifying audio tracks by genre. Not only would this model automate a portion of the musical feature extraction, but the components used in building the model could potentially be used to compare different songs in a recommendation system.
While music genres as a whole are inherently ambiguous, they are generally well-understood by listeners. User preferences frequently align with specific genres, so there is value in recommending content based on genre.
Strategy and Model
Data was collected from the Free Music Archive. In this dataset, 8000 30-second audio samples are classified into 8 distinct genres.
Audio samples were split using Harmonic Percussive Source Separation, then for each split component, 13 Mel-Frequency Cepstral Coefficients (MFCCs), as well as spectral contrast, were computed over several time windows. The mean, variance, and first and second time derivatives for each value were used as features.
An SVM with a Gaussian kernel was trained to predict genre given the statistics of the MFCC coefficients.
Results
In classifying 8 different genres, the model achieved 54% accuracy on a test dataset of 1600 samples.
The above figure shows a confusion matrix for the model on the test dataset. The precision/recall is fairly balanced across the classes, with the exception of Pop music. My reasoning is that Pop music is more ambiguous than other genres, as it typically overlaps with and borrows features from several different styles.
Given the inherent ambiguity and overlap in genre, one song is likely to fall under multiple genres, so it will be more effective to return multiple predictions for a single song, in order of relative probability as estimated by the model (decreasing).
With minor adjustments to the model, I was able to use the model to predict a probability distribution of genres for a given song, rather than the most likely genre. The following plots show the distributions for 2 very popular songs.
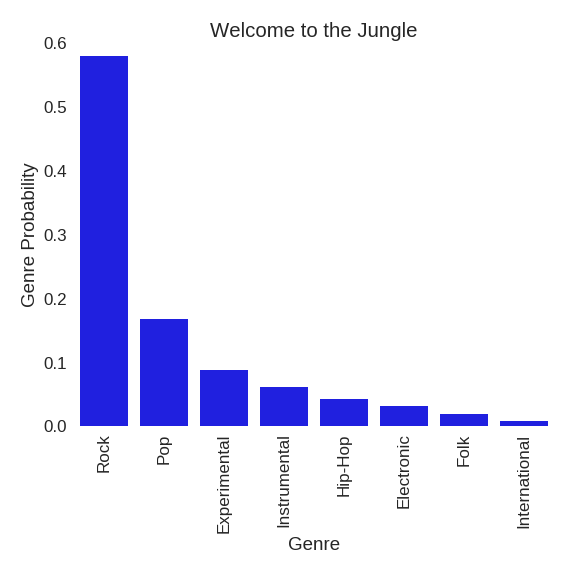
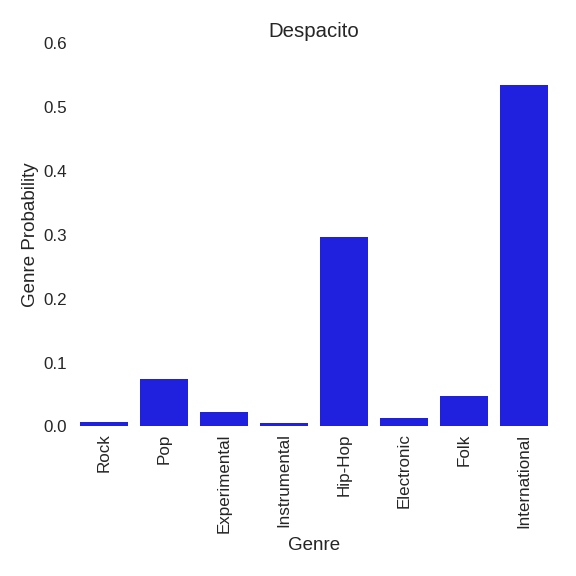
In this case, Welcome to the Jungle is primarily Rock and Pop, and Despacito can be interpreted as a combination of International and Hip-Hop music.
While deep learning techniques have seen success and occasionally stronger accuracy in audio identification, this approach has the advantages of scalability and being faster to adjust and implement.
Given more time and resources, future directions with this project would include:
- Incorporating NLP and lyric data to improve genre classification
- Utilizing other audio/spectral features
- Identifying different features from audio (country, decade, etc.)