Supervised machine learning utilizes various algorithms in building predictive models. While the work done under the hood is different between models, the API for training every machine learning model is essentially the same in scikit-learn:
model.fit(x,y)
model.predict(x)
This post is not meant to be an in-depth analysis of each algorithm and its inner workings. Instead, my hope that this gives a better idea of which models to choose for certain datasets and constraints. I’ll discuss factors including:
- Scalability
- Computation and memory
- Interpretability
The following table summarizes the pros/cons of several core machine learning algorithms.
| Algorithm | Pros | Cons | Notes |
|---|---|---|---|
| Linear Regression | Interpretable Fast training/prediction time Robust Structure is simple; just a single weight vector |
Requires several assumptions about error values Can't model complex, nonlinear relationships |
As simple as regression models can get Good for numerical data with lots of features |
| Logistic Regression | Probabilistically interpretable Fast training/prediction time |
Not inherently multiclass; requires building multiple one-vs-all classifiers | A binary extension to the linear regression model |
| Naive Bayes | Probabilistically interpretable Fast training/prediction Good with high-dimensional data |
Independence between features is a VERY strong assumption | Good for text data |
| Decision Tree | Interpretable Scale invariant; data does not need to be normalized before training Inherent feature selection and multiclass support |
VERY prone to overfitting | Great for categorical data |
| Random Forest | Can train multiple trees in parallel Very good with categorical features |
Multiple decision trees may be memory intensive Lot of hyperparameters to tune Harder to interpret than a single decision tree |
An ensemble variant to the decision tree |
| Gradient Boosting | Surprisingly effective at regression Very good with categorical features |
Prone to overfit Hard to interpret |
Another ensemble variant to the decision tree |
| K-Nearest Neighbors | Simple to interpret No training time Inherent multiclass support |
Offloads all computation to testing Memory intensive Prediction time does not scale well with dimensions or number of training points |
I do not recommend this algorithm in practice |
| SVM | Good in high-dimensional spaces Memory efficient |
Difficult to interpret Computation doesn't scale well with larger datasets Doesn't provide probability estimates Doesn't handle overlap/noise well |
Good for data with more features than training points |
| Neural Network | Can model very complex relationships Inherent multiclass support |
Lot of hyperparameters to tune Computationally expensive Memory intensive Impossible to interpret |
Good for image/video/sound data |
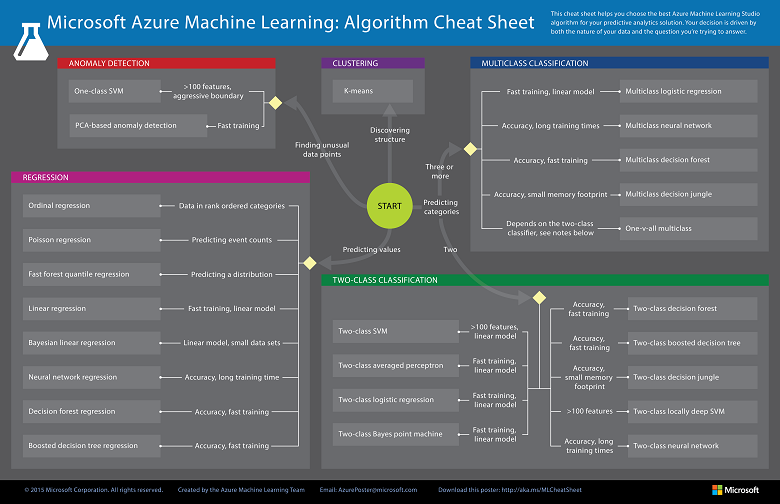
This flowchart from Microsoft Azure also gives a good basic idea.
{kind=link}